
Chapter 9: Mutations and Variation
Laura Merrick; Arden Campbell; Deborah Muenchrath; Shui-Zhang Fei; William Beavis; and Walter Suza
Introduction
Mutations are the ultimate source of all genetic variation. Mutations can occur at all levels of genetic organization, classified mainly as either chromosome mutations or genome mutations. Chromosome mutations are discussed in this module. Chromosome alterations involve either single nucleotides or fragments of chromosomes and are either small-scale (one or a few nucleotides substituted, inserted, or deleted) or large-scale (deletions, insertions, inversions, or translocations involving large segments of chromosomes or duplications of entire genes). Genome mutations—involving changes in number of whole chromosomes or sets of chromosomes—will be covered separately in the module on Ploidy—Polyploidy, Aneuploidy, Haploidy.
Genetic variation—dissimilarity between individuals attributable to differences in genotype—that is generated by mutations is acted upon by various evolutionary forces. Evolutionary processes that alter species and populations include selection, gene flow (migration), and genetic drift—whether or not plants are cultivated or wild. Evolution can be defined as a change in gene frequency over time. The way that plants evolve is dependent on both genetic characteristics and the environment they face.
Genetic variation results from differences in DNA sequences and, within a population, occurs when there is more than one allele present at a given locus. Major processes that affect heritable variation in crop plants are topics emphasized throughout the lessons of this course. Changes in gene frequencies within populations caused by natural selection can lead to enhanced adaptation, while changes caused by human-directed selection can facilitate the development of useful genetic variability and selection of superior genotypes. Selection is the differential reproduction of the products of recombination—both within and between chromosomes.
Genetic Resources
Historically plant breeders seeking sources of variability were constrained in choice of parental materials or plant genetic resources that were interfertile within closely related gene pools. But a range of new techniques such as mutagenesis, genetic engineering (transgenic or transformed plants), and in vitro methods (tissue culture, doubled haploids, induced polyploids) expand the source and scope of variability that can be used in crop improvement.
Our expanding understanding of the molecular basis of genetics has provided insights and technologies that further not only our basic understanding of genes and their regulation, but also provide additional tools for crop improvement. Molecular techniques enable breeders to generate genetic variability, transfer genes between unrelated species, move synthetic genes into crops, and make selections at the molecular, cellular, or tissue levels. Combining these laboratory techniques with conventional field approaches can shorten the time required to develop new or improved cultivars. The importance and application of molecular technologies are rapidly increasing.
These topics mentioned above—mutations, gene expression, genetic markers, sources of genetic variation, genetic engineering, and molecular breeding methods—will be briefly mentioned in this module, but covered in greater detail in the later courses including Plant Breeding Methods, Molecular Genetics, and Biotechnology and Molecular Plant Breeding.
- Recognize how mutations are classified and inherited, as well as how mutations affect structure, processes, and products of genes and chromosomes.
- Understand the basic principles of transcription and translation.
- Become familiar with sources of genetic variation for cultivated plants, including crop gene pools and genetic engineering methods.
Mutations as Heritable Change
Without heritable variation, any trait favored by selection will not be passed on to offspring. Mutation is defined as heritable change in genetic information. Mutations entail modification of the nucleotide sequence of DNA and consist of any permanent alteration of a DNA molecule that can be passed on to offspring. DNA is a highly stable molecule and it replicates with a high degree of accuracy. However changes in DNA structure and replication errors can occur. Mutation involves modifications in the sequence of bases in DNA transmitted through mitosis and meiosis.
A nucleotide consists of a sugar molecule (ribose in RNA or deoxyribose in DNA) attached to phosphate group and a nitrogen-containing base. In DNA or RNA molecules, each strand has a backbone of sugar and phosphate groups (Fig. 17).
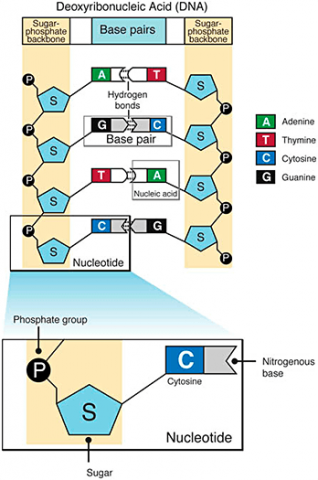
CHEMICAL BASES IN DNA AND RNA
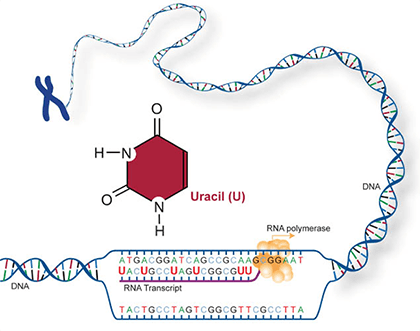
Two of the four nitrogenous bases in DNA—adenine (Fig. 13) and guanine (Fig. 14) are known as purines and the other two—cytosine (Fig. 15) and thymine (Fig. 16) are pyrimidines. Adenine, guanine, and cytosine are also found in RNA. Another pyrimidine known as uracil (Fig. 17) is the base used in RNA in place of thymine.
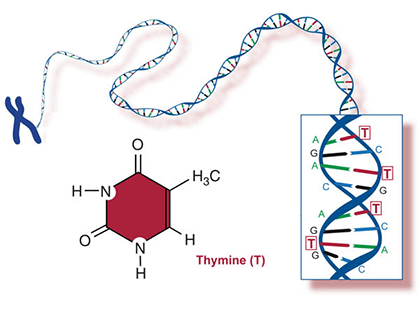
Some mutations occur in loci that encode for gene products such as proteins, and thus they may affect the processes of transcription, translation, or gene expression—processes that happen during the creation of proteins from the genetic code in DNA. But mutations also can occur in parts of the genome that do not code for any gene products (called noncoding DNA) or sequences that serve to control regulatory functions in the cell or chromosomes. For most loci, mutation changes allelic frequencies at a very slow rate and therefore consequences are negligible. Mutations may or may not change the phenotype of an organism. The majority of mutations that do occur are neutral in their effect and therefore do not have an influence on fitness. Some mutations are beneficial. But mutations can have deleterious effects, causing disorders or death.
Amino acids are a set of 20 different molecules used to build proteins. A peptide is one or more amino acids linked by chemical bonds (termed peptide bonds). Linked amino acids form chains of polypeptides (Fig. 18). The amino acid sequences of proteins are encoded in genes.
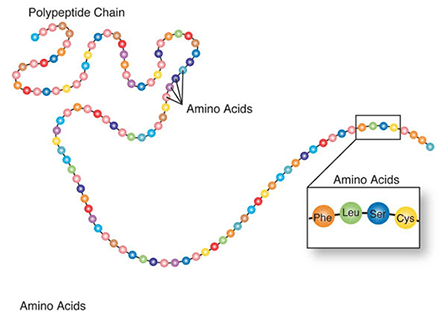
One or more polypeptides form the building blocks of proteins (Fig. 19). Proteins perform a variety of roles in cells.
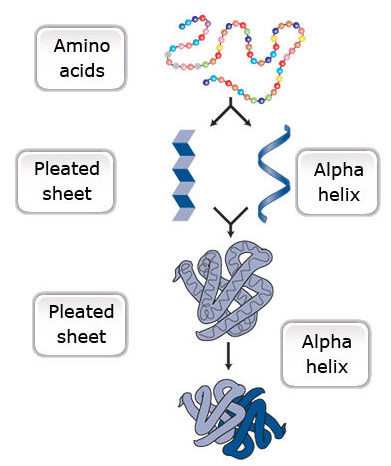
Primary protein structure is a sequence of a chain of amino acids.
Secondary protein structure occurs when the sequence of amino acids is linked by hydrogen bonds.
Tertiary protein structure occurs when certain attractions are present between alpha helices and pleated sheets.
Quaternary protein structure is a protein consisting of more than one amino acid chain
Types of Mutations
Classification of Mutations
Mutations can occur at all levels of genetic organization, ranging from simple base nucleotide pair alterations to shifts and rearrangements in sequences of nucleotides along fragments of chromosomes to changes in the number and structure of whole chromosomes.
A mutation is a change from one hereditary state to another, e.g., allele A mutates to allele a. For a given locus, the normal allele is referred to as the ‘wildtype’. Mutations are usually recessive and therefore their effects are hidden in heterozygotes. There are a number of common ways to classify mutations, including the following:
- causal agent
- rate or frequency of occurrence
- kind of tissue involved and its type of inheritance
- impact on fitness or function, or
- molecular structure and scale of the mutation.
Spontaneous vs. Induced Mutations
Depending on the cause, mutations can be either spontaneous or induced:
- Spontaneous mutations occur naturally with no intentional exposure to a mutagen. Spontaneous mutations can result from copying errors made during cell division.
- Induced mutations are caused by mutagens, either chemicals or radiation.
RARE VS. RECURRENT MUTATIONS
Recall from the module on Population Genetics, mutational events in a population can be classified into two categories based on frequency of occurrence:
Rare mutations (also called non-recurrent mutations) are defined as those that occur infrequently in populations. Rare mutations are usually recessive and occur in a heterozygous condition so that their effect on the phenotype is not apparent. Rare mutations will usually be lost from populations due to random genetic drift.
Recurrent mutations are defined as those that occur repeatedly and thus can possibly cause a change in gene frequency in populations. For a given locus, the rate of allele A mutating to allele a can be given as the frequency u per generation; a mutates to A at a rate v.
With the frequency of A symbolized as p and that of a symbolized as q, then at equilibrium, pu = qv, or q = p/(u + v) (see the Equation below).
[latex]pu = qv[/latex]
[latex]q= \frac{u}{v + u}[/latex]
Mutation Rates
Falconer and Mackay (1996) summarize the following key points about mutation rates and their frequency in populations:
- normal spontaneous mutations alone can produce only very slow changes of allele frequency;
- mutation rates are generally quite low for most loci in most organisms, occurring about 10-5 to 10-6 per generation or, stated another way, about 1 in 100,000 to 1 in 1,000,000 gametes carry a newly mutated allele at any locus;
- with respect to equilibrium in both directions (u and v) in natural populations, forward mutation (from wildtype to mutant; u) is much more frequent than reverse mutation (from mutant to wildtype; v); and
- an equilibrium state known as the mutation-selection balance can maintain deleterious alleles at low frequency; selection acts to eliminate deleterious recessive alleles, but very slowly when the allele frequency is low; even if the elimination process of selection is slow, an equilibrium occurs if mutation creates new copies of the deleterious allele.
Somatic vs. Germinal Mutations
Plants are multicellular organisms, but mutation typically starts from a single cell. There are two broad categories of mutations that are classified according to the type of cell tissue involved.
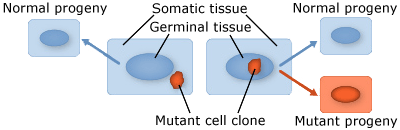
Somatic mutations occur in somatic tissue, which does not produce gametes. Somatic cells divide by mitosis and therefore through that process, mutations can be passed on to daughter cells. Somatic mutations may have no effect on the phenotype if their function is covered by that of normal cells. However somatic cells that stimulate rapid cell division are the basis for tumors in plants and animals. Somatic mutations usually occur as single events (typically in a single cell) in multicellular organisms or organs that lead to chimera, which is a part of a plant with a genetically different constitution as compared to other parts of the same plant. Somatic mutations are not transmitted to progeny (Fig. 1).
Germinal or germ-line mutations occur in reproductive cells that produce gametes, and therefore can be passed on to future generations. Germ cells or gametes are formed by meiosis. If a germinal mutation is inherited, then it can be carried in all of the somatic and germ-line cells of the offspring (Fig. 1).
Effects of Mutation on Fitness or Function
Mutations can affect fitness in various ways and can therefore be classified based on their effect on individual fitness:
- Deleterious mutations are those that are harmful and have a negative effect on phenotype, decreasing the fitness of the individual.
- Advantageous mutations are those that are beneficial and have a positive or desirable effect on phenotype, increasing the fitness of the individual.
- Neutral mutations have neither beneficial nor harmful effects.
- Lethal mutationsare detrimental and lead to the death of the organism when present.
Mutations can also be classified by their effect on gene function:
- Loss-of-function mutations either result in a gene product that has less function or one that has no function. Phenotypes associated with loss-of-function mutations are usually recessive. Many of the mutations that are associated with crop domestication from wild progenitors involve loss-of-function alleles (Gepts 2002).
- Gain-of-function mutations result in a gene product that has novel function. Altered phenotypes associated with gain-of-function mutations are usually dominant. Many of the changes in crop plants brought about by genetic engineering involve gain-of-function mutations (Gepts 2002).
However, it is important to underscore that not all mutations occur in genes or protein-coding regions of the chromosome, nor do all mutations that do occur in genes lead to altered proteins.
Point vs. Chromosomal Mutations
Mutations are often divided into those that affect a single gene, termed a gene mutation—also sometimes called a point mutation—and those that affect the structure of chromosomes, called a chromosomal mutation. These latter two classes of mutations will be covered in more detail after the concept of gene expression is introduced in the following section.
Point Mutation
Point or Gene Mutation
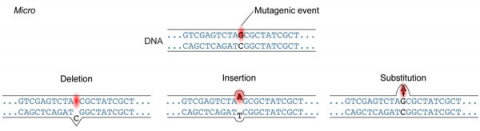
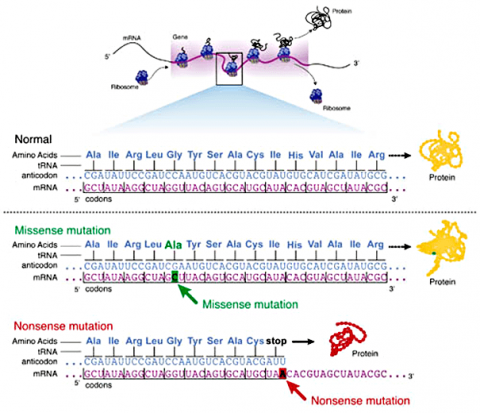
A point mutation is when a single base pair (or just a few) is altered (Fig. 2), an alteration at a “micro” level. There are two general types of point mutations: substitutions or insertions and deletions (the latter two are collectively called INDELs).
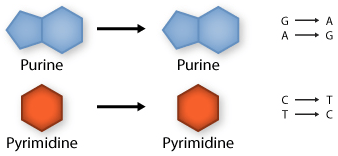
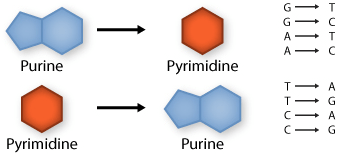
Base pair substitutions involve an alteration of a single nucleotide in the DNA. A substitution mutation can entail either a transition or a transversion:
Missense Mutations
Some substitution mutations have no effect on the protein coded for. One reason is because of the redundancy of the genetic code (recall that about one fourth of all base pair substitutions code for the same amino acid; such mutations are termed silent mutations since there is no change in amino acid that results from the substitution). Another reason for lack of effect is that even if a change in amino acid occurs (termed missense mutation), it may have no actual influence on the function of a protein (Fig. 3). Also any mutation located within a non-coding region of the chromosome will not be translated into a protein. Lastly, an altered gene may be masked by other normal copies of the gene present in the genome.
In certain cases, point mutations can have a significant effect—particularly when a substitution produces a stop codon so that the alteration causes the protein synthesis to halt before the protein is entirely translated, altering the entire structure. These are called nonsense mutations (Fig. 3).
Frameshift Mutation
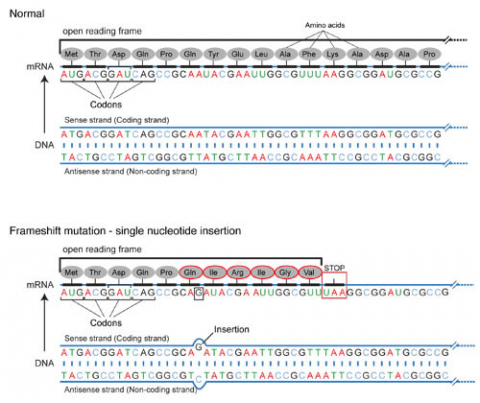
Base pair insertions and deletions are additions (INDELs) or losses of one to several nucleotide pairs in a gene (Fig. 2). Mutations that are insertions and deletions tend to have a much greater effect than do mutations that are base pair substitutions because they disrupt the normal reading frame of trinucleotides. Recall that each group of three bases corresponds to one of 20 different amino acids used to build a protein. Mutations involving base pair insertions and deletions are often therefore referred to as frameshift mutations. Under these circumstances the DNA sequence following the mutation is read incorrectly (Fig. 4).
Chromosomal Mutation
MUTATIONS INVOLVING CHROMOSOME SEGMENTS
Different cells of the same organism and different individuals of the same species generally have the same number of chromosomes, and homologous chromosomes are typically uniform in number and in the arrangement of genes along them. However, mutations can occur that alter the number or structure of chromosomes.
Changes involving chromosomal rearrangements entail the following basic types: deletions, duplications, insertions, inversions, substitutions, and translocations—alterations that occur at a “macro” level (Fig. 5).
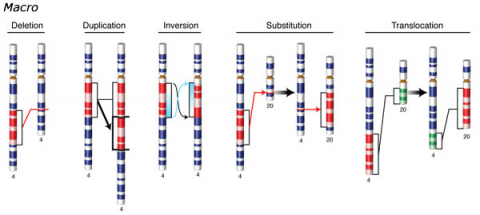
- Chromosomal deletions are when loss of a chromosome segment occurs.
- Chromosomal duplications occur when a chromosome segment is present more than once in a genome or along an individual chromosome. Mutations of this type can involve duplication of chromosome fragments of either noncoding regions or genes that do code for a protein or other gene product. Gene duplications have been important events in the evolution of many crop plants, for example in cotton.Both chromosome deletions and duplications generally result from unequal crossing over during meiosis, whereby one gamete receives a chromosome with a duplicated segment or gene and the other gamete receives a chromosome with a missing or “deleted” segment.
- Chromosomal inversions happen when two breaks occur in a chromosome and the broken segment turns 180°—reversing the orientation of the sequence—and then reattaches. Such inverted segments may or may not involve the centromere (termed pericentric inversion vs. paracentric inversion). A consequence of chromosomal inversions is that they either prevent crossing over or if crossing over occurs, the recombinants may be eliminated during meiosis. During meiosis, inverted chromosome segments may form loops in order to pair with the same (non-inverted) sequence on homologous chromosomes.
- Chromosomal insertions (not pictured) and chromosomal substitutions are when gain of an extra fragment of chromosome occurs.
- Chromosomal translocations entail a change in the location of a chromosome segment. Commonly translocations are reciprocal and thus result from exchange of segments between two non-homologous chromosomes.
Transpositions
Chromosome segments can also be translocated to a new location on the same chromosome or to a different chromosome but without reciprocal exchange; both of the latter types of mutations are termed transpositions. A transposon (also called a transposable element) is a DNA element that can move from one location to another. These mobile DNA sequences commonly occur in some genomes and can themselves cause other mutations to occur, depending on where they “transpose”.
Discussion
Mutants and mutations are best known in the context of horror films. In the context of plant breeding and more generally crop production, discuss the consequences of mutations—are they good or bad? Which kinds of mutations are desirable and which ones are undesirable?
Sources of Variation
Sources of Genetic Variability
Plant breeding is dependent on differential phenotypic expression. Loci with only one allelic variant (homozygosity) in a breeding population have no effect on the phenotypic variability. Variation can be introduced to breeding populations by various methods:
- hybridization and recombination by sexual reproduction within or between species or populations
- genetic transformation or genetic engineering using recombinant DNA methods
- induced or spontaneous mutations and transposable elements (transposons)
- chromosome manipulation via change in chromosome number and structure (ploidization) [to be discussed in the module on Ploidy—Polyploidy, Aneuploidy, Haploidy]
- tissue or cell culture techniques [to be discussed in the module on Ploidy—Polyploidy, Aneuploidy, Haploidy]
CONCEPT OF CROP GENE POOLS
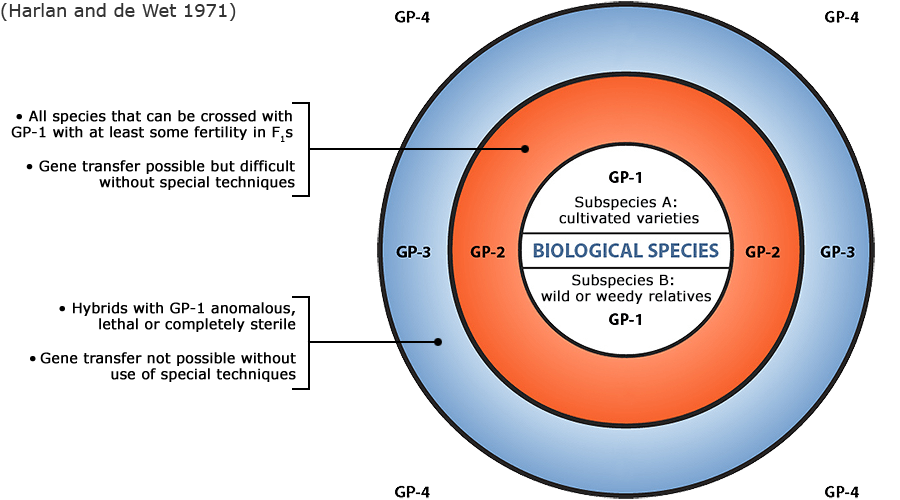
Plant germplasm is a term used to refer to an individual, group of individuals or a clone that represents a genotype, population, or species. With reference to a given crop and its wild and cultivated relatives, the concept of gene pool (all of the genes shared by individuals in a group of interbreeding individuals) has been applied to categorize a broad range of plant genetic resources according to the ease of gene transfer or gene flow to the particular crop species (Harlan and de Wet 1971).
Gene Pools
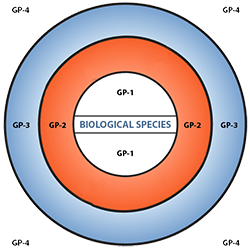
Figure 6 depicts three main categories in the original scheme outlined by J. R. Harlan and J.M.J. de Wet (1971) defined as:
- primary gene pools (GP-1, consisting of biological species that can be intercrossed easily without problems of fertility in the progeny; including both cultivated varieties and wild progenitors of the crop),
- secondary gene pools (GP-2, consisting of more distant relatives that can be intercrossed with difficulty and result in diminished fertility in the hybrids and later generations; including both cultivated and wild relatives of the crop), and
- tertiary gene pools (GP-3, consisting of very distant relatives that can be hybridized with the crop only with special techniques, e.g., embryo rescue, due to problems such as sterility, lethality and other abnormalities),
With the addition of a fourth gene pool that contains synthetic variants and lines with nucleic acid sequences that do not normally occur in nature. Methods of genetic engineering relevant to this fourth gene pool category will be covered briefly in the next section of this module.
Genetic Engineering and Plant Transformation
Genetic engineering, also referred to as recombinant DNA or rDNA technology or gene splicing, involves moving a DNA segment from one organism into another to ‘transform’ the recipient or host. Through a broad range of techniques encompassing biotechnology (for example, gene manipulation, gene transfer, cloning of organisms), novel genetic diversity can be generated that extends beyond species boundaries or can be designed and synthesized de novo in molecular laboratories. Potentially, any gene from any species, as well as synthesized segments, could be transferred into a plant using genetic engineering.
Gene transfer can be applied for a variety of objectives:
- Add different or new functions
- Alter existing traits—amplify, suppress, or prevent the expression of a gene already present in the recipient’s genome
- ‘Tag’ and isolate genes in the recipient plant
- Tool for basic gene regulation and developmental studies
Requirements for Gene Transfer
In order to efficiently generate transformants (plants that possess DNA introduced via recombinant DNA technologies), the transformation system used must satisfy several requirements.
- Ability to get DNA into host cells in high concentration to increase the probability of incorporation into the host genome
- Incorporation into the host nucleus (or chloroplast if the objective is to minimize gene flow by pollen or to produce a large quantity of therapeutic proteins)
- Integration into host genome (or stabilization as an autonomous replicon—a plasmid or minichromosome)
- The introduced gene is expressed and translated properly
GENERAL STEPS
- Identification and isolation of a gene that confers a desired trait.
- Introduce the gene into a suitable construct and carrier, such as plasmids or bacterial vectors, for delivery into the host.
- Introduce the DNA into the host.
- Identify and select transformants.
- Regenerate plants.
- Assay for expression of the trait.
- Test for normal sexual transmission, or asexual propagation, of the transferred gene.
The carrier that will deliver the DNA into the host should have certain features.
- Sites in which to insert passenger DNA sequences (gene of interest, plus a selectable marker gene if the gene of interest does not allow for easy selection of transgenic plants).
- Sequences to mediate integration into the host genome
- Selectable marker gene for identification and selection of transformants
Usually, the DNA sequence to be transferred into the host is joined with other sequences to facilitate transfer, incorporation, and expression of the gene. Here’s a generalized construct for a T-DNA vector, a carrier derived from an Agrobacterium tumefaciens plasmid.
Introduce the DNA
Several methods are available to introduce the DNA into the host.
- Vector-mediated transfer
- Direct DNA uptake—DNA cannot be taken directly into cells having a cell wall so protoplast must be used.
- Microinjection—DNA is injected directly into the host nucleus
- Acceleration of DNA—coated particles – particles are “shot” into the cell (particle bombardment or gene gun)
Genetic transformation plays an important role in modern-day crop improvement. The first transgenic plant was created in 1983. By 1996, there were already 1.7 million hectares of genetically modified (GM) crops and this number increased 100-fold to 170 million by 2012 and is still increasing. The majority of the GM crops (soybean, corn, cotton, papaya, canola and sugarbeet) were created by the use of Agrobacterium tumefaciens (vector-mediated transfer) to resist either herbicides or insects. Herbicide-resistant crops greatly simplified weed management where mechanization in agriculture is high. Insect-resistant crop plants produce stable yields. The tremendous expansion of GM crop production, however, is not realized without controversies. There is currently an intense public debate over the impact of GM crops on human and animal health. Besides health issues, other concerns surrounding GM crops are whether they can create superweeds by crossing to related weeds, become invasive or cause unintended harm to wildlife.
Bt Gene: Vector Constructs
Let’s follow the transfer of a Bt gene into a plant.
The Bt gene was identified and isolated from Bacillus thuringiensis, a bacterium. The gene produces a protein that has toxic effects on Diptera (flies), Lepidoptera (butterflies and moths), and Coleoptera (beetles) species. Soybean was transformed using Agrobacterium tumefaciens. Two different T-DNA vector constructs carrying the Bt gene and one control construct were tested for effectiveness in transforming soybean cells and expressing the Bt toxin (Fig. 7).

Bt Gene: Transformation
Leaf disks from soybean plants were infected and cultured on selective (+) and control (-) media—the selective medium was gradually enriched with an antibiotic (Fig. 8). At time 1, the leaf disks were infected with the respective constructs. Conditions were used to promote callus production and growth. At time 2, the plates were evaluated for calli formation.

Transformed cells are able to develop into calli. These are selected and transferred to a medium containing both antibiotics and growth regulators that promote the formation of shoots and roots (Fig. 9).
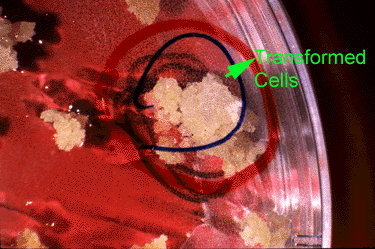
Bt Gene: Insect Resistance Evaluation
Plantlets are regenerated and transferred to pots containing sterilized soil. Nearly all of the regenerated plants exhibited normal morphology and vigor. A few had chlorophyll deficiencies— these were eliminated from the study. The remaining regenerated plants were evaluated for insect resistance. An equal number of insect larvae are placed on each regenerated plant; plants are isolated to prevent insects from moving among plants.


Bt Gene: Insect Resistance Data Analysis
After several days, the dead larvae on each plant are counted. Here are the data.
| Gene Construct | No. of Plants Showing % Larvae Mortality | |||
| < 25 % | 25% – 50% | 51% – 75% | 76% – 100% | |
| Intact | 14 | 7 | 0 | 0 |
| Fusion | 2 | 6 | 2 | 20 |
| Control | 29 | 0 | 0 | 0 |
Study the information in the above table. Look for any patterns in the data. Interpret the data by selecting all of the true statements
Advantages and Disadvantages
Although recombinant DNA technologies have some problems, the technologies offer several advantages.
| Advantages | Disadvantages |
|---|---|
| Characters can be transferred from divergent species without the limitation of sexual compatibility | Difficult to identify and isolate gene |
| Single gene or gene sets can be transferred into important breeding lines without the deleterious effects of linked genes. | Insertion is random |
| Transferred character ordinarily exhibits dominant, single-gene inheritance | Difficult to obtain proper expression |
| Still must screen at whole plant level and under normal production conditions | |
| Expensive |
Despite its limitations, plant transformation has additional advantages over conventional breeding. Millions of cells, with regeneration capacity, can be screened for the desired trait in a few weeks. A desired gene can be transferred without the necessity of generations of breeding to move the trait from one line into another. Recombinant DNA technology can also be used to place synthetic genes into plant genomes.
The insertion point of the transferred gene cannot be controlled. Plants contain an estimated 500,000 to 5,000,000 kilobases (kb) of DNA. The maize genome, for example, has more than 4,000,000 kb. Generally, transferred DNA involves relatively small amounts of DNA, on the order of 10 kb, so the insertion ordinarily has little effect on chromosome pairing, recombination, or mitosis. The incorporated gene may or may not affect other genes in the recipient genome, depending on where it inserts.
- In a non-coding region—no effect on the recipient genome
- In a gene that occurs in multiple copies in the genome—the effect, if any, is usually not detectable.
- In a single-copy gene—inactivates or alters the expression of the single-copy gene.
Insertion into a single copy gene is rare. If it does insert into a single-copy gene, inactivation or alteration of the expression of the disrupted gene may be undetected, or may cause favorable or adverse results—albino and other chlorophyll deficiencies are common problems.
Why do these characters generally exhibit dominant, single-gene inheritance? Traits acquired via gene transfer often add a function to the transformed plant. Because the transferred trait is unique in the transformant’s genome, the transformant does not possess any contrasting alleles for the character. Thus, its inheritance is expected to be dominant and as a single gene.
Gene transfer is also used to suppress or eliminate, or to amplify the expression of genes already possessed by the host plant. These are also usually designed to behave as dominants.
Expression involves many steps, all of which must occur properly to obtain the desired phenotype. Expression must be appropriately regulated.
- Generation of the gene’s product-requires proper transcription, mRNA processing, and translation.
- Location of expression must be in the appropriate plant part.
- Timing of expression needs to occur at the right stage of the plant’s development.
- Amount needs to be at an effective level or extent of expression to generate the desired phenotype.
For Your Information
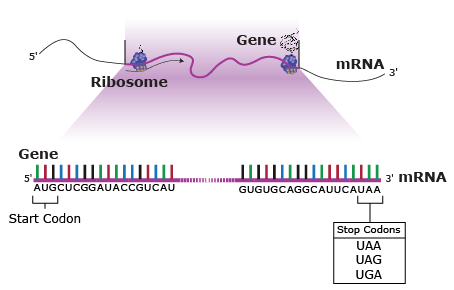
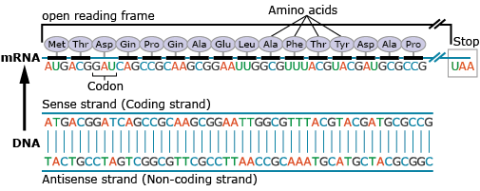
Amino acids are the building blocks of polypeptides, proteins, and enzymes. The order of the nucleotides on a strand of RNA, as transcribed from DNA, determines the order of amino acids in a polypeptide. Each group of three consecutive nucleotides of the RNA codes for a particular amino acid, or the beginning or end of the message. These triplets of nucleotides are called codons (Fig. 20).

The genetic code, or instructions from a gene that direct the cell to make a specific protein, is usually based on the messenger RNA (mRNA) sequence (Fig. 21). In mRNA, uracil (U), rather than thymine (T), is the nucleotide base that complements adenine (A) on the DNA strand; guanine (G) complements cytosine (C) in both DNA and RNA.
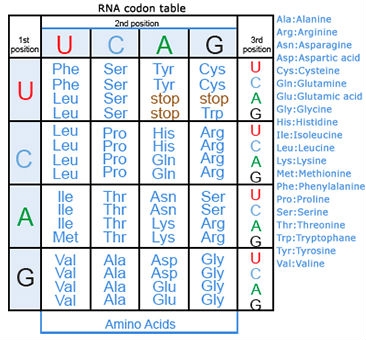
Here are some examples of codons:
- A-A-A and A-A-G signal the amino acid lysine (Lys)
- G-A-A and G-A-G code for glutamine (Gln)
- A-U-G signals the start of a coding sequencing and codes for methionine (Met)
- U-A-A, U-A-G, and U-G-A are stop codons.
Of the 64 possible combinations of three bases, 61 specify an amino acid, while the remaining three combinations are stop codons, or trinucleotide sequences that indicate the end of the message, terminate translation of that mRNA section, and signal a “stop” to protein synthesis (Fig. 22).
The portion of a DNA molecule that, when translated into amino acids, contains no stop codons is referred to as an open reading frame (Fig. 23).
References
Collard, B.C.Y., M.Z.Z. Jahufer, J.B. Brouwer, and E.C.K. Pang. 2005. An introduction to markers, quantitative trait loci (QTL) mapping and marker-assisted selection for crop improvement: the basic concepts. Euphytica 142: 169-196.
Falconer, D.S. and T.F.C. Mackay. 1996. Introduction to Quantitative Genetics. 4th edition. Longman Pub. Group, Essex, England.
Harlan, J.R., and J.M.J de Wet. 1971. Towards a rational classification of cultivated plants. Taxon 20: 509-517.
Gepts, P. 2002. A comparison between crop domestication, classical plant breeding, and genetic engineering. Crop Science 42: 1780-1790.
Nageswara-Rao, M. and J.R. Soneji. 2008. Molecular genetic markers: what? why? which one for exploring genetic diversity? Perspectives-The Science Advisory Board, 8 September 2008 [available online September 23, 2011, http://www.scienceboard.net/community/perspectives.210.html
Neuffer, M.G, E.H. Coe, and S.R. Wessler. 1997. Mutants of Maize. Cold Springs Harbor Laboratory Press.
NIH-NHGRI (National Institutes of Health. National Human Genome Research Institute). 2011. Talking Glossary of Genetic Terms. [available online February 6, 2017, http://www.genome.gov/glossary/
Interruption of the transcription or translation of DNA such that a gene is not expressed phenotypically.
An experiment in which variables studied occur naturally and are not manipulated by the researcher.
Nurseries that facilitate planting and cultivation of materials at times other than the growing season in the target market region. For example, programs in temperate regions may seek facilities in the alternative hemisphere where seasons are flipped.
An experiment in which variables studied occur naturally and are not manipulated by the researcher.
An essentially derived variety is predominantly derived from another variety (“initial variety”) and conforms to the initial variety in the expression of the essential characteristics of the initial variety. An essentially derived variety may be obtained through methods such as backcrossing, transformation, and mutagenesis.
A method used to determine the response relationship of data. This method determines whether data is linear (form y=ax+b), parabolic (y=ax2+bx+c), or higher order.
In glass, e.g., a test tube or flask, rather than in a living organism.
